Tradle on P2P & Local Cloud
Personal Data in multi-device world
We are working on the idea that Personal Comuting is entering a new major cycle, which will be based on software defined networks, software-defined compute and software-defined storage for personal use.
As we are exploring here the design for data management in multi-device world using our chosen framework, Hypercore. You can find a lot more information on Hypercore in this rapidly growing FAQ.
Take a look at Issues on this repository for the themes we are actively experimenting with.
What is Hypercore?
Monopolies are not good
The web's hub and spoke technical architecture is the reason we now have monopolies with billions of users, the size of which was never seen before. Billion dollar fines for them seem to be issued every year now, but this is not a solution. We need a new P2P architecture and Hypercore is it.
P2P tech is hard to create, but it is finally entering mainstream
P2P architectures and applications are much harder to create than centralized, they are often less efficient (BitTorrent's download super-speeds are an exception) and investors are less interested, as they do not produce monopolies that create outsized returns.
Yet, we live in the age of the rise of decentralized and P2P tech renaissance. Notable is the whole crypto space, which helped launch decentralized VPNs, like Orchid, decentralized live streaming like Theta.tv, etc.
Some P2P technology is inherently very slow. Luckily Hypercore is designed for real-time, and works in time-sensitive video streaming and decentralized filesystems and database scenarios.
Why Tradle on Hypercore?
It has been our long held belief that data not services should be the first class citizens on the Web. Enterprises understand that, and Data Governance is at the core of well run businesses. Yet on the Web and mobiles we still build applications that hoard the data. From this, the notion of data sharing between applications arises. Tim Berners-Lee and W3C failed to change that with Semantic Web. May be they failed due to obscure and complex formats they invented, or may be we collectively did not yet then get scared enough of a rapidly centralizing Web.
So what if we built apps the other way around, in a way where all data would belong not to the app / website owner, but to the user. App would visit the data, help the user with some insights and either go away, or go to sleep. Data would remain user's and never get exfiltrated, or possessed by the app. Later a different app can visit the same data and draw new insights. No need for sharing data between apps, as when data leaves you, you lose control over it. This does not mean we never share data, we do, with friends and teams, but not with apps and their owners.
Hypercore, with its data-first design fits this paradigm.
We need a flexible foundation for Personal and SME Applications
We explored a plethora of systems for privacy-focused first-person data management. Most systems are focused on chasing AWS with Enterprise-centric offerings. Existing solutions for Personal Cloud are focused just on data (mimicking Dropbox), not applications. Others, like NextCloud, are full blown packages of applications not cloud-native and not designed as a foundation for building new apps.
Our requirements include Personal Cloud that will then evolve to SME Cloud. We have already built an Enterprise Cloud system for the banks (we call it MyCloud), so we know the higher end requirements quite well. Hypercore will give us many things we need, such as reliable messaging for our Transactional Messenger, data sharing for teams, will provide the Data Integrity we need for compliance, and Change Data Management for building search indexes, Data Lakes and to run ETL jobs.
What we have found in Hypercore is a highly modularized and composable framework, with many standard APIs, and reusable abstractions that allow developers to plug in alternative implementations. Unlike any competing P2P framework, Hypercore's design allows for a much wider class of privacy-first applications, which is on our roadmap.
Hypercore is also like a puzzle of a hundred pieces. It is its strength but also its complexity. It is not easy to build on top of today, and this limits its potential. At Tradle we would hope to help higher-level developers with tools to build P2P apps really fast.
What was the Initial Impulse?
Initial impulse for the design exploration of Hypercore has arrived from the Data Sovereignty demands we got from the banks and the governments for our open source Digital Identity product. With Tradle server, called MyCloud, we had decentralization figured out, or so we thought.
Tradle MyCloud is installed by its users under their own AWS account, so they end up with their own Tradle installation. It is serviced by Tradle support staff, but from the outside, without any access to their data or operations. We call it Private SaaS.
We started Tradle with the notion that Credit Bureaus, and any other identity aggregators, are a systemic risk for our economy and personal safety. With the Equifax disaster, in which Equifax lost detailed financial information of all working Americans, we now know for sure that data aggregators are evil.
So with MyCloud we solved data ownership issue. But Data Sovereignty became a new and powerful phenomena for us as AWS data centers are present in only 15 countries at the moment (similar with other Cloud Hyperscalers). Besides, in many countries storing sensitive data in the data center owned by a foreign operator is not permitted. And, interestingly, in Europe it has recently become a sore point and a new policy for Data Sovereignty is forming. It is not surprising, as Snowden's revelations showed, that whole population data, centralized in a small number of corporate hands, are a powerful magnet for governments. The temptation is just too great. And now there is also a US Cloud Act.
Local Data Centers have lost to AWS and other Hyperscalers, so what is the Point?
In the past 10 years there were many failed attempts to create Open Source AWS alternatives.
The most massive effort was OpenStack. But AWS is a very fast moving target and simulating all that it does (160+ services and counting), became impossible. OpenStack was designed by Rackspace initially, but later adopted a multi-stakeholders committee process, which turned out to be very complex to manage and just plain too slow to chase AWS.
Luckily, in the past 10 years major components of Cloud's virtualization and networking have become part of the standard Linux kernel or have emerged as Open Source projects. This is KVM and WireGuard, FireCracker and Containers, S3-compatible storage like Min.io and scalable low-management databases like Facebook’s RocksDB and CockroachDB, built on top of it, by former Google Spanner engineers.
Many other innovations are happening on the Edge of the network, outside of the AWS stronghold. This is Fly.io serverless offering with FireCracker and Redis, CloudFlare serverless with Node V8 Isolates (like Workers Threads) and Key-Value store, Fastly.io serverless with blazingly fast WebAssembly.
And finally, there is an under-appreciated gem of Hypercore.
Tradle on AWS can be adapted to move to Hypercore
Luckily Tradle uses only a small subset of AWS services, and this makes the task manageable. See our current AWS architecture:
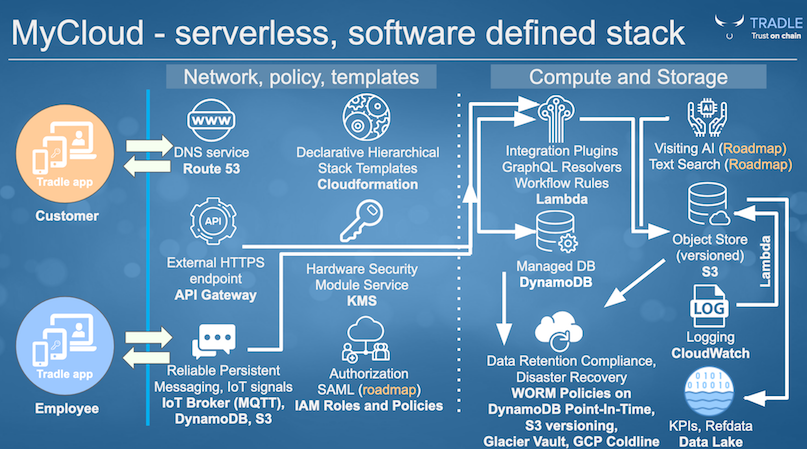
What makes this task even more practical is that Tradle MyCloud already uses an emulation layer for AWS, called Localstack. Localstack is sufficient to run and debug Tradle MyCloud, but does not robust underlying components to run in production environment.
We need a solid base that can be deployed in any Local Data Center, removing our dependency on AWS. This document outlines the steps we can take by replacing one by one its components with the production-ready components for singe-tenant use cases, with replication, reliability, security and performance guarantees.
Assembling a modern Cloud stack on Hypercore
Matching a vast array of AWS services is a daunting task, and it is not our goal. We choose to focus on a Simple Cloud foundation, sufficient to run a Personal Cloud. Communications, virtualization, networking and other aspects of the Cloud will be described in Simple Cloud document, while here we focus on Hypercore, that can help address many aspects of data, sharing and communications.
What do we gain from Hypercore, at the high level?
Data Sovereignty
Ability to offer Data Locality / Residency / Sovereignty for private-first offline-first P2P applications, with functionality and convenience similar to and surpassing the centralized, Google-style apps.
Data Continuum
Ability to build apps that work in the Cloud and on local PCs and mobiles. Many cloud-native systems only work in the Cloud, which limits their scope of use, and makes them extremely difficult for developers to debug and test, leading to a huge loss in productivity. AWS is notoriously difficult in that respect.
Rethinking AWS from P2P first-principles
The core idea of Personal Cloud is to give individuals access to Infrastructure and Platform level of services (IaaS and PaaS), which are sold only to organizations. Direct infrastructure ownership provides the level of isolation, security and privacy that most closely resembles PCs at home. This Personal Computing platform would then allow to build truly personal apps, which we abandoned with SaaS, giving SaaS vendors access to all our data.
To make infrastructure acceptable to people, it needs to be simple.
Simplifying Cloud for individuals
We must use abstractions users already know.
Undo and redo
With the help of Hypercore any type of data, document, database, files can support undo / redo right off the bat. Versioning of files like undo / redo.
Forego the Object store
S3 Object Store today is the staple of cloud services. But it is very different from the file system that people already understand. Users will get lost in storage classes, and different ways of working with them. Storage classes have capabilities, guarantees and costs, defined by durability, access time, ability for random access, immutability, searches, replication to other regions, etc.
We should implement these capabilities without asking users to sign up for some additional services, and understand upfront their different levels of service and costs involved.
For example, the following policies could apply:
- Least used files should move to cold storage automatically, and should be available from cold-storage immediately (albeit with slower access). Sparse replication will come very handy here.
- Photo albums are much less sensitive to the loss of one of thousands of pictures, than personal databases. Videos could be moved to cold storage more aggressively. Hypercore's streaming from cold storage comes handy here.
- IoT signals could go to cold storage directly. IoT signals never need to be edited, so can use cheaper non-editable storage (S3 for example. only allows to replace objects, which helps it to be cheaper).
- Delete protection. Hypercore offers versioning that allows to undo deletes. Deleted files could be moved to cold storage, and auto-removed after 30 days.
With that said, storage classes and other capabilities above should be offered to app developers on the granular level with the help of file / folder metadata, while preserving file system abstraction.
Database
Personal database, that people would use for simple planning and tracking should behave in a robust and most predictable way. It should support multiple devices sync out-of-the-box, seamlessly, behind the scenes (using Hypercore's native replication capabilities).
Underlying syncing should use protective measures, such as conditional writes (update only if version read is not different) to avoid overwriting data, incremental adds so that operations are commutative, and with CRDT and causal clocks to facilitate conflict-free merges when a person made conflicting changes.
Users interact directly with data, database is just a file, like xls. The viewer and editor for database are built in.
Identity
Identity is a big subject and Tradle has spent years getting deep understanding of it. Cloud services offer a multitude of identity services which are complex and not suitable for personal use. Yet identity is critical for building apps and controlling access to data.
The way mobile apps and web apps ask us to create an app-specific identity, with a new login and password, is insane. Reuse of passwords and their general weakness is one of the reasons we have many data breaches.
Identity should be intrinsic to our actions in the Cloud, and we should not need to manage it so much. With Personal Cloud Tradle is redefining person's relationship with the apps, making data always personal, it does anymore belong to the apps. Apps are visitors, helpers, service providers, they come to our home, Personal Cloud, do what we ask them to do, and go away, taking nothing of ours with them. In this setup, identity changes its meaning to the app.
More on this later, but note that WeChat's vast apps ecosystems is greatly enabled by identity.
What makes Hypercore suitable for Tradle?
Data Durability, Load balancing, and Mobility
Data Durability
Hypercore has built-in capabilities for data replication. This can be used to replicate files and databases in-Data Center (DC) and inter-DC. This provides durability of data, with the resilience to hardware failures.
Load Balancing
We can build load balancing, routing requests to another machine to perform computation on the desired data replica. It also adds to durability, as it allows scheduled and emergency hardware maintenance by forwarding traffic to other machines and Data Centers.
Mobility
It can help migration of data to allow users to move to another Data Center at will.
Durability, Load Balancing and Mobility for Databases
It is not enough to have just file replication. Replicating databases is much harder. Replication of databases is provided by Hypercore and it can be used for durability, load balancing and mobility. It also can be used for analytics applications that are performed on a replica, offloading the operational DB.
Hyperbee is compliant to Level API, which allows it to become a drop-in replacement for AWS DynamoDB, with a Dynalite adapter. This is simpler for personal use, while for teams, and for e-commerce we will need to explore additional Hypercore tech for streaming sort-merge, see below.
Data Integrity, Digital Signatures and Compliance
Protects every data item from unauthorized modifications and assures that the old data is intact (Thus is similar to blockchain, where all transactions are added to a Merkle tree and new blocks linked to old ones).
In Hypercore, the writer digitally signs any addition or change. Previous versions of the data are kept and can be retrieved later. This creates a very nice audit trail.
Note that it still lacks secure timestamping and allows the author to roll back to a previous version and start again, without the peers that arrived after the fact noticing it. Both can be prevented with a blockchain-based binding (e.g. such as used by Tradle).
This can further benefit from qualified digital signatures compliant to eIDAS in EU, equivalent US laws E-Sign Act and UETA), and other jurisdictions that accept digital signatures in the court of law. This would also be critical for forensic investigations in regulated industries and for criminal investigations (This lack can be alleviated by Tradle with its finance-grade identity management and associated digital signatures to alleviate this).
Uniformity
Hypercore allows to discover peers in the network and connect to them to consistently and reliably exchange all types of data. Hypercore uniquely works for messaging, files, huge media, IoT streams and databases. Uniquely, it allows to stream all those data, a notion that existed for media, but was not attempted before for databases.
Recovery
Hypercore uniquely works for both files and databases. Provides point-in-time restore from any past versions of the data state. This simulates both the DynamoDB point-in-time backup / restore and S3 object versioning. This capability can also be used as snapshots, as it allows to checkout the store, tagged at a particular version. This may be used for devops and for development. It can also be used in forensic investigations for regulated industries and in criminal investigations.
Shared files and folders (like Dropbox or Google Drive)
Hyperdrive, one of Hypercore components provides the core capabilities. It allows to share a drive with the family, friends and teams. To compete with Dropbox and Drive, it needs durability, typically associated with the Cloud. Inherent replication capability of Hypercore comes handy as any sharing with peers increases the durability, but it is not enough. What is missing also is mobile and browser implementations and easy UI, permission system, notifications, etc.
Shared document editing like Google Docs and Google Slides
Because Hypercore is designed for immediacy of real time data exchanges, it can be used for simultaneous editing. Its P2P nature allows it to work without a central site. What is also needed is intelligent document merge. There are two community projects that provide the missing capability. YJS and Hypermerge.
Like with the Hyperdrive, the remaining issue to be solved is the always-online nature of competing non-P2P services.
Offline-first, local-first
All data is available when offline. Messages and media (of any size) are delivered from mobiles to server and back with full reliability, in the presence of intermittent or rare connectivity.
Use cases and potential apps
Group messaging
Using publish / subscribe capability of Hypercore (TBD - need to describe further).
Direct media sharing
Supports large-size media. E.g. 150mb file can’t be shared on WhatsApp or Skype. Sharing between two users over the Internet, while bypassing the server (in most cases), makes it faster, cheaper, more secure, protecting other essential freedoms and more resilient against surveillance.
There is still work to be done for making Hypercore more private, e.g. improve Hyperswarm to not reveal IP addresses when not on VPN, perhaps with the help of I2P.
Local file sharing, like Apple Airdrop
This is supported by local peer discovery (with the help of MDNS). Allows sharing on the local network, without going to the internet. This is another privacy and security enhancing capability.
Research data and DB sharing
Support for super-large file sizes is important for scientific data sets. Support for BitTorrent-stile download acceleration by downloading from multiple universities simultaneously is also a critical capability. Allows verifying integrity of chunks of data loaded in parallel from untrusted peers.
But let's not forget Hypercore's totally unique capability for Database streaming, which allows Petabyte-scale DB served remotely, without a database server.
What new killer apps will this novel database approach create? Here is one possible example, a Database CDN. We are used to static files served on the edge, but a Hyperbee data structure can be piped onto AWS S3, and streamed from it without a server, with the help of this module.
Any Database Server can be accessed remotely and many can serve huge databases. But a server needs a machine, and human resources associated with its operational management. Such costs are detrimental for pay-per-use model of the cloud and especially to a new popular with developers class of Serverless applications.
Let's repeat this point again: Hypercore's database structure gives us an ability to access the database remotely, without a database server, and without a database client, too. This point needs to sync in so that engineers can pause and ask themselves the question - how will this reshape multi-tier applications? What applications will benefit from this the most?
Live streaming
Hypercore enables live streaming as allows to upload video and for viewers to start downloading media, before the whole file is uploaded. It also allows to pause, rewind, fast-forward and view from any point.
Concerts and podcasting. Note that although critical, Hypercore is not a complete set of capabilities needed for live streaming apps, e.g. they need video transcoding, micro-payments. Note Dazaar, a Hypercore team's recent collaboration with Bitfinex on micropayments for streaming apps based on Hypercore.
Security cameras: at the door or inside (nanny cam). Such non-P2P apps are a gross privacy concern.
Other Home sensors.
Car signals and cameras. Cars are expected to generate the majority of data on the Internet, at the rate of terabytes per hour.
Wearables signals (fitness, health, location for child / elderly monitoring)
Building and Equipment signals streaming.
Drone cameras.
Other IoT signals
Note that live streaming also needs always-online capability for content sharing, like any other P2P apps.
CDN
Hypercore can be used to build a CDN for distributing files to the edge, and distributing load between the replicas. It is static storage friendly. Files and databases can be served from a static storage, as in CDNs. Additionally, due to BitTorrent-like functionality, it can help CDN in the following ways:
Saves CDN bandwidth costs by bandwidth sharing, turning media watchers into uploaders
Accelerates download as it allows to load chunks from multiple peers simultaneously. This is especially important for 4K, VR and 3D printing content.
Real-time incremental CDN updates. Many CDNs take significant time to replace old files. And many require the full flush of current files. Hypercore can help optimize both with immediate updates and Change Management events.
Note that Hypercore team still has work to do on efficient editing of large files. Editing existing files is inefficient, it currently results in file duplication. This is not good for videos and for FUSE-mounted Hyperdrive that has a big database file or a log file that needs to be appended to.
Headless CMS
Headless Content Management System separates a backend and a front-end.
- CMS Backend can be built on Hypercore
- CMS Front-end needs collaborative editing, that is one of the Hypercore use cases
Continuous Backup
Personal and team data backup. Usable on mobiles, desktops, and servers. Hypercore is archive-able to S3.